
A ogni pagina di Game Engine Architecture me ne rendo sempre più conto: realizzare un motore di gioco serio è un lavoro di una difficoltà estremamente elevata.
L’intenzione per la tesi di laurea (frequento il corso di Informatica presso Unica) sarebbe quella di riuscire nell’impresa, ma francamente sono sicuro che riuscirci anche solo in parte sarebbe un gran successo.
Se da una parte, quindi, mi accorgo che realizzare un motore di gioco diventa un sogno sempre meno raggiungibile (almeno in solitario e in soli 2 anni), d’altra parte proseguo nella lettura del libro Game Engine Architecture, per un motivo molto semplice.
E’ bello vedere, attraverso questo libro, come la creazione di un motore di gioco porti con sè delle necessità particolari, come ad esempio quelle di gestire delle risorse (audio, modelli 3D e molto altro), sfruttare al massimo l’hardware, semplificare il lavoro di un team e far comunicare tra loro delle componenti software ben separate ma interdipendenti (es. gestore della memoria, gestore della fisica, gestore del rendering…).
In ognuna di queste componenti, la natura (golosa di risorse) di un videogioco costringe a delle scelte che raramente diventano necessarie per un qualsiasi altro software.
Questo si ripercuote sulla scelta di alcune strutture dati, sulla particolare gestione della memoria e su molto altro. Facciamo alcuni esempi.
L’utilizzo di numerose malloc/new e free/delete in C/C++ rallenta tantissimo il programma perché a ogni chiamata si cambia la sua modalità di esecuzione (da user mode a kernel mode e viceversa).
Per ovviare a questo problema si evita assolutamente di allocare/deallocare memoria all’interno di cicli (verrebbe ripetuta più volte) e si cerca, invece, di prevedere già in anticipo quanta memoria verrà usata e allocarla una sola volta (es. prima di caricare un livello sappiamo più o meno quanta memoria verrà utilizzata) in modo da effettuare una sola volta il passaggio da user mode a kernel mode e viceversa. Una volta fatto ciò si effettuano operazioni sullo heap in modo tale che pesino il meno possibile e con un po’ di astuzia.
E a proposito del livello… spesso (anche in giochi abbastanza vecchiotti tra l’altro) si utilizzano strutture dati particolari per la sua gestione, vedi lo stack double-ended.
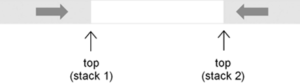
Da una parte si caricano le risorse utili per TUTTO il livello (o anche il gioco, dipende sempre dalle esigenze), dall’altra quelle che si utilizzano solo momentaneamente.
Non vengono utilizzati due stack separati perché ciò porterebbe ad effettuare operazioni sullo heap: la memoria necessaria allo stack double-ended è stata già allocata in precedenza, quindi occorre anche riscriversi a mano tutta la gestione delle operazioni su questo particolare stack, con un occhio di riguardo all’ottimizzazione.
Parlando di ottimizzazione… che dire dell’allineamento dei dati? In C e C++ è possibile ottimizzare al meglio l’esecuzione di certe istruzioni da parte della CPU allineando i dati in maniera tale che la CPU, appunto, utilizzi il più basso numero possibile di cicli.
La CPU accede in maniera più veloce ai dati se questi si trovano in un indirizzo di memoria divisibile per la dimensione della variabile, quindi vale la pena utilizzare un pochino di spazio in più per ogni variabile ma avere poi la certezza che questa sia allineata correttamente spostandola manualmente di qualche byte se necessario (si lavora sempre sulla memoria heap).
Due link per approfondimenti a riguardo:
- https://en.wikipedia.org/wiki/Data_structure_alignment
- http://www.agner.org/optimize/optimizing_cpp.pdf
Ma non finisce qui: siamo abituati a utilizzare Git o un altro software di controllo di versione per gestire del codice sorgente. Ciò viene comodo perché i sorgenti sono leggeri e, soprattutto, sono file di testo (e Git, si sa, fa miracoli con questi).
Potrebbe essere necessario, però, utilizzare un VCS per gestire delle risorse che, come si può immaginare, sono file binari e soprattutto sono pesanti. E qui i soliti VCS, sebbene sempre funzionali, potrebbero portare altri problemi che necessitano di essere risolti (più difficile l’utilizzo concorrente del VCS a causa dei file binari, file di dimensione maggiore comportano utilizzo maggiore della banda, ecc.).
Probabilmente aggiornerò questo articolo man mano che scopro cose interessanti riguardo alla progettazione di motori di gioco.
Testo che sto leggendo, se non lo conoscessi per i file binari esiste l’estensione LFS, Large File Storage per GIT ed è possibile adoperarla sia in remoto, su GITHUB e BITBUCKET, che in locale. Non mi è capitato di appurarne l’efficacia ma è una soluzione al “problema” dei file binari.
Ciao Andrea, non ne avevo sentito parlare e conto di informarmi a riguardo.
Mi viene da supporre che diventa comunque impossibile per un VCS qualunque gestire in maniera perfetta un file binario, per il semplice fatto che mentre i file di testo sono facili da manipolare (il supporto della concorrenza si basa su ciò), per ogni formato di file binario si ha una manipolazione diversa. Una soluzione a questo inconveniente, citata sempre nel testo, è quella di preferire l’utilizzo di tanti file più piccoli a quello di un unico file enorme (contenente ad esempio le risorse grafiche) in modo tale da facilitarne la gestione per il VCS e non solo. Dopo si tratterebbe di pacchettizzare il tutto, se proprio serve un file grande.